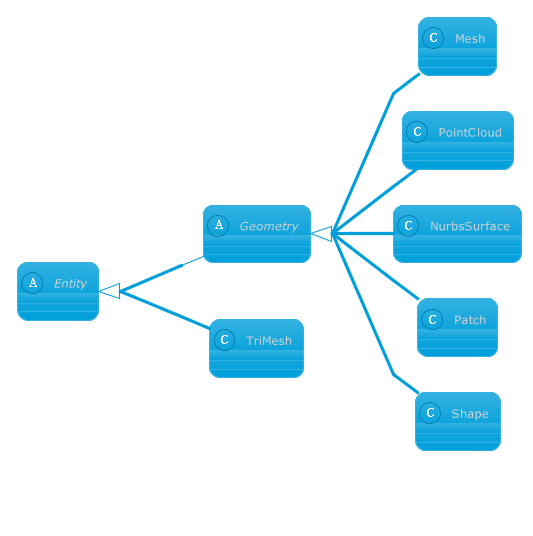
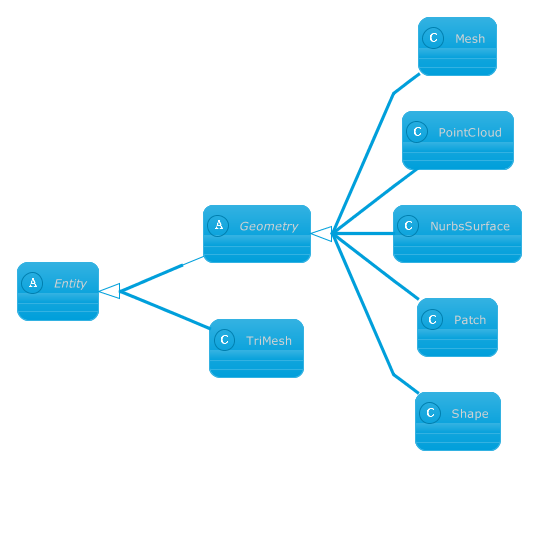
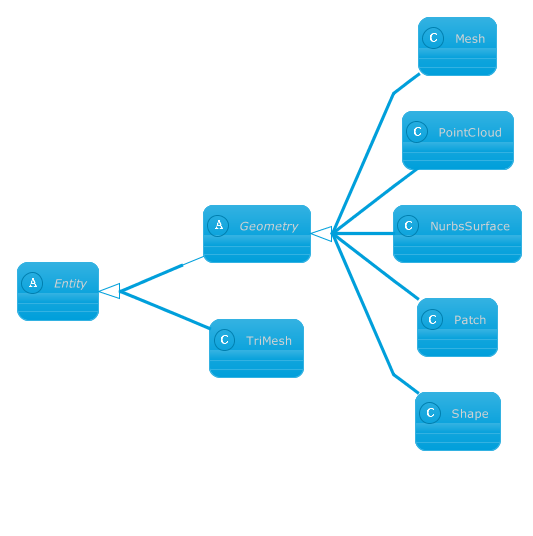
Class Libraries & REST APIs for the developers to manipulate & process Files from Word, Excel, PowerPoint, Visio, PDF, CAD & several other categories in Web, Desktop or Mobile apps. Develop & deploy on Windows, Linux, MacOS & Android platforms.... length ); // 1 Shape assertAreEqual ( 3 , shapeLayer... length ); // 3 knots in a shape assertAreEqual (- 16127182 ...
{kind=link}
{kind=link}
{kind=link}
{kind=link}